Computer Algorithms are not magic – they’re a defined set of instructions set out by a Software Engineer to achieve a certain goal. The goal of LeetCode problem 675 is to cut down trees in a forest, cutting the trees in ascending order and counting the minimum number of steps required – the ‘difficulty’ comes through obstacles in the forest that you cannot walk through, potentially preventing you from cutting down the tree’s.
In the video above, the obstacles are depicted in the grey colour. Within the force-directed view, a red node indicates the current starting position and green indicates the next tree we’re heading for (note how green becomes red as we walk to each tree and cut it down). A purple node indicates the ‘frontier’ of the BFS, whilst pink nodes indicate those nodes we have already visited in the search. All others nodes are blue.
The video is just a snippet, head over to the demo site to view from start to finish.
Producing this visualisation was surprisingly simple – D3 is used to create the force-directed graph you see on the left, and Three.js is used to mimic the ‘forest’ we’re trying to chop down. The most complicated part of the solution is structuring it in such a way that the algorithm execution can be ‘slowed down’ and visualised; this was achieved through a mix of JavaScript Intervals and Promises. The code can be found on GitHub – it was put together in an afternoon so please don’t judge!
So what next? Debugging is typically performed in an Integrated Development Environment (IDE) – however, for a lot of new and aspiring Software Engineers, this environment can be difficult to navigate. What if we could debug in an environment that we are all accustomed to – a highly visual, interactive environment. This is the purpose of the next stage of this piece of work (if I can find the time!) – I will release this LeetCode problem as an integrated web based IDE that visualises your code as it executes. Will you implement a BFS solution, or perhaps a more heuristic solution such as A*?
If you’re as frustrated with the lack of insight into your JIRA projects as I am – I’ve got the tool for you.
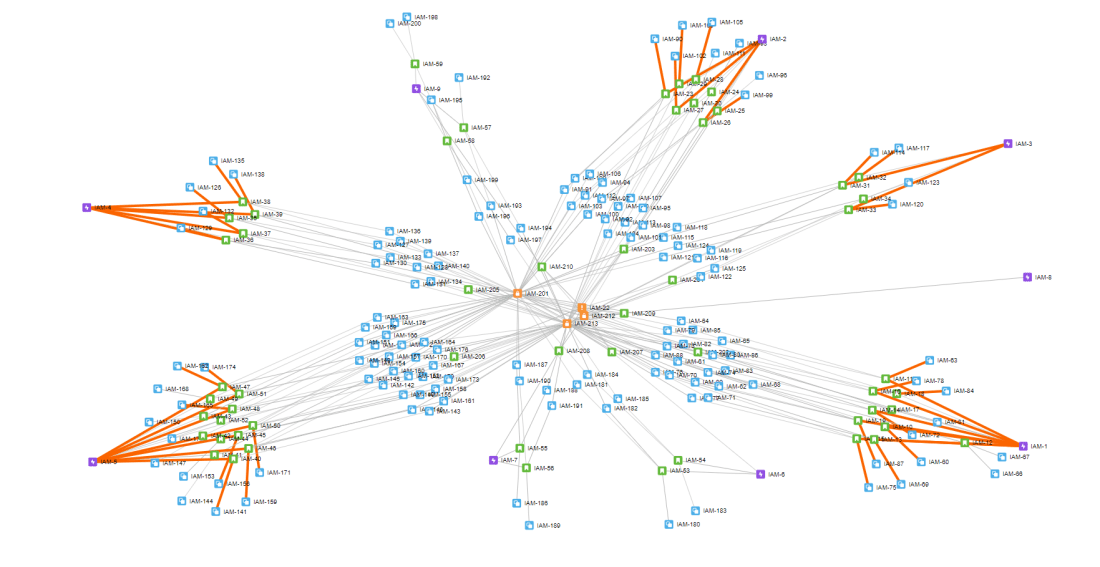
Use the JIRA Issue Visualiser, for free, and view the structure of your JIRA projects in less than a minute.
You’ll be asked to authorize via JIRA Cloud OAuth – once complete you can then paste in a JQL query. For example, to produce the above I just wanted to see all items within my project, so my query was ‘project=IAM’. You can read about JQL queries on the JIRA help-site if you are not familiar. You must be using JIRA Cloud and not a local JIRA installation to use this tool.
NOTE: this tool has been glued together in an evening. It is not user friendly or close to the finished article. However, in its current state, it can still be as useful to you as it is to me. If you’re interested in working on the tool, please see the bottom of this post.
Once you have provided a query, wait 20-30 seconds (you will just see a blank page whilst the data is retrieved).
You can click and drag the core JIRA issues (epics and stories) to organise the graph in a way that makes sense. You can also click on an issue to open it in JIRA.
NOTE: if the query returns more than 400 items at present, it may take longer than 20-30 seconds to load.
Why develop the JIRA Issue Visualiser?
Forget Agile, Scrum and Pillars – the successful completion of a project is dependent on the successful completion of a number of tasks inline with client expectations (cost, time, etc.) through a dedicated, talented team. Fundamentally, JIRA provides a way of organising those tasks into helpful chunks, and supercharges a collaborative approach to their completion. JIRA goes on to do 100x more, but at its core, it’s a task management system.
JIRA offers a number of great reports out of the box that attempt to give you a view of your project – however I feel they don’t give me a view on a page that tells me:
How dependent are my issues upon each other?
And in particular, what tasks are causing the biggest issues (RAIDs)?
What’s the status of my tasks?
How big / complex is the project?
I looked at a number of options – in particular using PowerBI plugins to create force-directed graphs, but they just weren’t flexible enough. Having used D3 before, I knew I could spin up something to meet my current requirements, but would also be flexible enough for the future. I created the JIRA Issue Visualiser and use it multiple times per day – I hope it can be as useful to you as it is to me.
Architecture
The diagram below outlines the high-level architecture for the JIRA Issue Visualiser – the core components include:
When the user retrieves the static HTML (and JavaScript) from S3, the code checks to see if there’s an access token available – if not, the user is redirected to the OAuth JIRA endpoint
The user logs into JIRA Cloud and authorises their credentials against the JIRA Issue Visualiser – following this, the user is redirected back to the resource in S3, with an authorisation code in the query parameters
The static page retrieves the authorisation code from the query parameters and sends it to AWS Lambda to be swapped for an access token
The Lambda function sends a request containing the authorisation code to JIRA (along with private credentials such as the client secret)
JIRA responds with the Bearer access token
The access token is returned to the users browser (note Lambda is stateless and therefore does not maintain any sort of application session – I didn’t want to integrate DynamoDB or similar at this point)
The user enters a JQL query which is sent to Lambda along with the access token
The call can not be made from the browser direct to JIRA due to CORS limitations on JIRA cloud and the resultant restriction this puts on browser CORS security
Lambda makes a call to the Issue Search REST endpoint, passing the JQL and access token. Due to the limitations of JIRA only returning 100 issues per API call, Lambda will make n number of API calls to retrieve all issues
JIRA responds with issue information including issue links and subtasks
The combined list of issues is returned to the users browser where it is rendered into a force-directed graph by D3
Future Enhancements
The code for the 2 Lambda functions and HTML / JavaScript can be found on GitHub – feel free to contribute (message me on LinkedIn to get started). This is by no means a finished product, future work could include:
Retrieving issues from JIRA concurrently
Remembering the access-token on page refresh so the user doesn’t have to re-authorise
Improve UI/UX (i.e. not using JavaScript prompts to retrieve a JQL query!)
Move the UI to a more future-proofed architecture (i.e. an SPA)
The ability to update force-directed graph properties (charge, gravity, etc.) on the page
Contextual menu containing useful information regarding the issue without having to click it
The query will display related nodes where the related node is a node also returned by the JQL query – it should work regardless