Disclaimer: I am not working on the UK Coronavirus Contact Tracing App – this is my own analysis and thoughts.
Contact Tracing apps are appearing in the news almost daily – they’re seen as one of the key enablers to reducing lockdown measures. But how do they work?
If these apps are going to be the number 1 app in App Store’s over the next year, I think it’s important people know how they work. This post attempts to offer you an explanation.
I am not working on any contact tracing applications but I have the upmost respect for those that are – as this article will highlight, this isn’t about software engineers sitting down at their keyboards. This involves the collaboration of politicians, health professionals, law professionals, engineers (across hardware and software), and more. Thank you.
So how do you collect 40TBs worth of data and spend £3m in the process?
High-level Architecture
Architecture 101 will teach you about the 3 Tier Architecture – at the top you have a Presentation Tier interacting with your users and at the bottom you have a Data Tier storing the data generated by the system. In the middle you have an Application Tier plumbing both layers together.
My theoretical Contact Tracing app has the following architecture. Don’t worry – each box in the diagram below will be explained throughout this post.
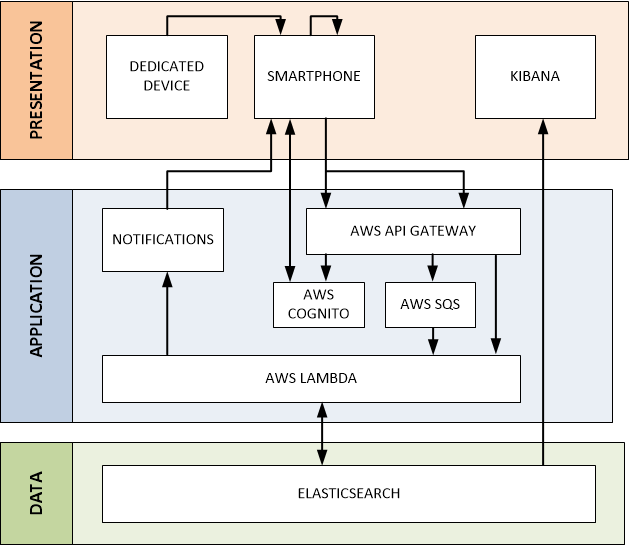
Presentation
The Presentation Tier is the window into the Contact Tracing app for end users – whether that be you and me on our phones or professionals using dedicated tools. There are 3 core components:
- Smartphones – the primary tool in determining whether 2 people have come into contact and upload this information to a central server. It also allows users to report any symptoms they may experience to warn other users that they need to isolate.
- Dedicated Devices – for those that do not have smartphones, cheap devices with extremely long battery life can be distributed to also track person-to-person contact.
- Kibana – a tool to enable the professional community to analyse the data collected.
The remainder of this section explains these components in further detail.
Collecting Contact Report Information
A Contact Report is data describing the coming together of 2 people. But how do you know if 2 people are near each other in an automated, omnipresent way? Radio.
Smartphones use a lot of radio – when you make a cellular phone call, send a text, stream Netflix over your WiFi or download health data from your smartwatch via Bluetooth. But which radio technology is best suited to determine when 2 people are near each other?
Bluetooth LE
Bluetooth is the technology of choice – it operates in the 2.4GHz radio spectrum but at a much lower power than cellular and WiFi meaning it’s 1) friendlier to your battery, and 2) localised. If we can use Bluetooth, what information do we need to transmit to determine whether or not 2 people have passed each other?
We may be familiar with the terms IP, TCP, etc. these define a stack of protocols that allow us to send data across the Internet. But they’re not applicable everywhere – they’re quite heavy. Transmitting data in a Bluetooth environment does not have the same complexity as transmitting data over the Internet. Just as motorways have barriers, emergency telephones, etc. the street you live on doesn’t – different protocols are used in different environments. In Bluetooth, the important protocol to discuss is GAP.
GAP defines 2 types of devices, a Central and a Peripheral. A Peripheral has some data to offer – your smartwatch for example is a Peripheral in that it can tell your phone what your heart-rate is. The device looking for this data is therefore the Central. This relationship doesn’t have to be read-only, centrals can also write. For the sake of a contact tracing app however, it only needs to read.
A Central device is made aware of peripheral devices through advertisements packets – they’re like the person outside the airport holding your name up on a sign. The Advertisement Packet can merely inform the central of the devices presence, or it can contain additional information such as a name, the services it offers, and other custom data.
We can start to see how this may work – I’m walking along the street and my Bluetooth radio is listening across the various Bluetooth advertisement RF channels (of which there are 3), looking for other devices. Given the power at which Bluetooth signals are transmitted by the antenna on a device, it’s safe to assume if you pick up an advertisement packet, you’re within a stones throw of the person (ignoring walls, etc. – a concern raised regarding the reliability of contact tracing apps). We’ve detected an advertisements packet – great! How do we turn that into something useful?
Other contact tracing applications such as CovidSafe will connect to a device upon discovering a peripheral via an advertisement packet. Once the connection is made, it will read data from the device. This requires a fair bit of radio communication which would be nice to reduce. Furthermore, if the 2 devices can’t connect because the receiver signal strength is below the radio sensitivity (after all, they are walking away from each other and Bluetooth is short range), we’ve lost the contact even though we knew they were in the area as we saw an advertisement packet! Can we include some identifying non-identifying information in the advertisement packet that maintains privacy and reduces radio communication?
Every Bluetooth advertisement packet is sent with a source and destination address. Imagine you had the address 123, if somebody else knew that, they’d have a way of tracking you within a 15 meter radius over Bluetooth. That’s not good. To prevent this, the Bluetooth LE spec recommends periodically changing the address to avoid the highlighted privacy concerns – which Bluetooth chip manufacturers thankfully abide by. So we can’t use the Bluetooth address to identify a user as it may change. What other options do we have in the Advertisement Packet? (Identity Resolving Key (IRK) is a mechanism to remember devices – i.e. so you don’t have to keep reconnecting your watch!).
A developer can add up to 30 bytes of custom data to a Bluetooth advertisement packet – that data can be categorised inline with the Bluetooth specification. Within frameworks such as Apple’s Core Bluetooth, developers are limited to setting a device local name and a list of service UUIDs. Each Bluetooth application on a users phone can transmit different advertisement packets. By setting the device local name to an ID that means something in the context of the wider contact tracing application, we’ve a way of identifying when 2 people have come into contact. That thing is a Contact Token.
Contact Token
Every device in the contact tracing ecosystem has a unique identifier, often known as a Device UUID. This is a static ID – mine could be 1234. It contains no personal information but is unique to me. That’s great, but I can’t advertise that indefinitely or like the problem Bluetooth is trying to solve with the ever changing addresses, I can be tracked! This is where a Contact Token comes in.
A Contact Token is a somewhat short-lived identifier (couple of hours) that the Contact Tracing app knows about (i.e. it knows what user is using the token) but that other Bluetooth devices only know about for a couple of hours before it changes (therefore meaning you can’t be indefinitely tracked). You may recognise someone in a crowd from the clothes they’re wearing, but when they change their clothes the next day, you’ll have a hard time spotting them in the crowd.
Each device advertises a Contact Token once it has registered it with the application server (more on that later). When a device receives an advertisement, it informs the server that it has come into contact with the token, sending the token of the remote device, the local Device UUID, and a timestamp. On server-side, the contact token is correlated to the remote Device UUID and stored.
To prevent the user from being tracked, the Contact Token must be refreshed. But we’re talking about 48,000,000 people – we can’t do this every minute, the Transactions per Second (TPS) would be too high (think of TPS as frequency – I can ask you to do a push-up every second for 10 minutes, but you won’t be able to keep it up for long, I’d need to lower the frequency). If we change the token every 3 hours, we achieve a TPS of 4,000 – acceptable.
So that allows us to send a Contact Report to the contact tracing app backend systems and respect privacy – but when do we send these reports? As soon as they occur?
Sending Contact Information
Once we’ve identified a contact, we need to send that data to the server. But much like the TPS issues identified regarding the Contact Token – when sending contact reports, the frequency is increased by a factor of 10! Why? We walk past a lot of people each day!
In a typical day at work, I would imagine I walk past at least 100 people. A typical walk to work takes 10 minutes and I probably walk past a person every 10 seconds. That’s 60 people and the day hasn’t even started.
If there are 48,000,000 people utilising the app daily – you can imagine the volumes. 4,800,000,000 contacts per day across the population. Not only that, they probably occur over a 12 hour period between 0700 and 1900.
That’s a TPS of 111,111… ouch! No system can handle that. How can we reduce it? Batches.
Apple and Android support background execution of applications, however to preserve battery life, there are limitations. Whilst you can’t ask your app to do something every 2 seconds, there is support for Bluetooth ‘events’ – whenever an advertisement is received, your application can process it in the background. As contacts are discovered, we can add them to a cache and once that cache reaches a certain size (let’s say 50), it can be flushed to the server. This would result in a TPS of 2,222 – acceptable.
However, there are drawbacks. What if we have contacted 49 people and are then at home where we see nobody – those contacts will not be flushed to the server until the following morning when we venture outside and walk past 1 more person – this could result in delayed isolation notifications as the central system does not know of contact reports. Whilst some of these contacts may have been registered by the other person (you see my advertisement and I see yours), they may not have. Is this acceptable?
How do we handle contacts from coworkers and family members whereby we’re with them most of the day? To reduce the load, as Contact Token are replaced every 3 hours, we can cache the token and if we have already encountered it, refrain from sending the contact to the server.
Importantly, these decisions are not just technology based, they require input from politicians, health professionals, and more. Furthermore, they may be dynamically tuned during the live operation of the application.
Reporting Symptoms & Receiving Warnings
When a user reports that they have symptoms, all contact with that user in the past N days will be retrieved from the database. Each contact will then receive a notification (i.e. via the Apple Push Notification Service and Android equivalent) informing them to stay at home. How far we distribute these notifications is largely based on the R0 of the virus – the average number of people an infected person will infect. You can see a very simplified probability tree below where a single person is infected in a population of 13; infections can only traverse the lines between the circles. Furthermore, it is true that R0 is 1 for each population of 4 people (i.e. in a group of 4 people where 1 is already infected, 1/3 of the uninfected people will be infected).

At what breadth do you stop sending isolation warnings? Health professionals would have to decide, based on the R0 of the virus, at what probability they’re willing to stop sending notifications (too many notifications and people won’t trust the app is reliable). The R0 in the UK is approx. 0.5 and 1.
Apple & Google Frameworks
One of the main issues I see with current implementations of tracing apps is background execution. An app is considered in the background once it has been opened and the user then returns to the home screen without ‘swiping up the app’ (on iOS). However, many users frequently close their open apps, meaning the app will not be in the background and listening for or advertising packets over Bluetooth. This is where I would like to see improvements made in the frameworks Apple and Google are currently working on (although they’re taking it a step further).
Dedicated Device
What about those who do not own a smartphone? How might they participate?
As the name states, Bluetooth LE is Low Energy – embedded devices running off coin batteries can last for days to months. A potential solution therefore is a cheap, embedded device that can be distributed and integrated with the system.
I have created a basic proof of concept using a SmartBear BLE Nano board which can be seen below.

This device only has Bluetooth capabilities (to keep power consumption at a minimum), so how does it upload contact report information to the server and how are owners of these devices informed when they’re asked to isolate?
We know that receiving an advertisement packet is the trigger to upload a contact report to the server – in the smartphone example, given one of the devices receives an advertisement, the contact will be uploaded to the server. But in this case, if only the embedded device receives the advertisement, the contact won’t be uploaded to the server as there’s no radio providing internet connectivity.
A potential solution is to cache these contact reports and only when the chip can maintain a solid connection with a smartphone does it transfer this data to the phone which relays it to the server (ensuring to take care of man-in-the-middle attacks).
What about receiving isolation warnings? As is explained later on in this post, users verify their accounts via SMS. When a user receives their embedded device, they register it online, providing the system with a telephone number. A message can then be sent to the number if they are required to isolate.
So that’s the process from contact to sending the contact report to the server. Once the data is persisted centrally, we need a mechanism to make sense of it. Kibana.
Analysing the Data – Kibana
Kibana is a data exploration, visualisation and discovery tool. In other words, it allows people to make sense of large quantities of data in a somewhat user-friendly way.
Utilising Kibana, professionals in their respective disciplines can slice the data to understand a myriad of metrics that will aid in the decision making processes to enable the country to return to normal in a safe and controlled way. It can help answer questions such as:
- Where are infections occurring?
- Are people who receive isolation warnings actually isolating? (i.e. is our strategy effective)
- R estimation validation
- Immunity – are people reinfecting?
Application
The Application Tier is what ties the data collection in the Presentation Tier with the persistent, centralised storage of that information in the Data Tier. This Blueprint focuses on a serverless AWS architecture given the execution environment (12 hours of immense usage followed by 12 hours of very little usage), however solutions in other cloud and non-cloud environments are possible.
There are 2 types of inbound transaction (ignoring sign up, etc.) the Application Tier must support:
- Registering a Contact Token – the user device must receive a response from the Application Tier before it can start advertising a Contact Token. It has a TPS of approx, 3,000.
- Report Contact – the user device informs the Application Tier of a contact between 2 people. It requires no confirmation. It has a TPS of approx. 2,000.
However before we send any of this data, we need to ensure it’s coming from someone that we trust.
AWS Cognito
Privacy is double-edged sword – on the one side it protects the user, but on the other side is has the potential to degrade data quality and subsequently user experience. If users can sign up for a service without verifying themselves in any way, those with malicious intent will take advantage. There are a number of ways to prevent this through verification:
- Digital Verification – Email / Phone Verification, but also image recognition to match a taken picture against a driving license picture, etc.
- Physical Verification – attending an approved location with ID
Given the environment, this solution utilises SMS verification – whilst the details regarding the owners of numbers is private, this information can be accessed through legal channels and may violate some of the security principles.
AWS Cognito is the PaaS Identity Management platform provided by AWS. It’s where users validate their password and in response gain access to the system.
AWS API Gateway
Once the user has authenticated with AWS Cognito and received permission to access the system (via an access token) – they can use this token to make authenticated calls to the API Gateway. The first transaction will be to register a contact token.
When communicating with the API Gateway to register a Contact Token, the message is synchronous meaning the user (or more specifically, the users phone) won’t advertise the contact token until the AWS API Gateway has said it’s OK to do so. The Contact Token will be stored in the database before a response is returned to the user. An AWS Lambda function will handle this request and is explained further on.
Unlike the synchronous contact token transaction, we don’t need to wait for the contact report to be added to the database before our phone can continue with its business. Rather, as long as the AWS API Gateway says it has our contact report and will handle it, we can trust it do so. This is known as asynchronous communication. This asynchronous communication can be mediated through the use of queues – and as if my magic, AWS have an offering – the Simple Queue Service (SQS).
AWS Simple Queue Service (SQS)
As has already been alluded to, volumes in a system such as this are huge. Even with batching contact reports (remember the groups of 50), we would still produce 96,000,000 messages per day. If each message takes 0.5 seconds to process, that’s 13,333 hours if processing them sequentially. We need a place to store contact reports so we can process them in parallel – this is where SQS and AWS Lambda come in. Queues allow work to be dropped off somewhere with a fast TPS to be picked up and processed by systems with a slower TPS.
For now, think of Lambda as the ‘code’ (known as a Lambda Function) that takes contact reports off the queue and stores them in the database. If we can run multiple Lambda Functions in parallel, we would reduce our elapsed execution time. You can execute up to 1000 Lambda Functions in parallel which takes our elapsed execution time to 13 hours. That seems to work, but can we improve?
If we take batches of 10, so 10*50 and assume 1 second to process, it would take 1000 parallel Lambda Functions 3 hours to clear the queue. Often time, that majority of the execution time is not the business logic, but the overhead of spinning up of the environment, etc. to process the batch.
Whilst the queues may be empty during the night, during the day the queues will ensure end user devices can send contact reports to the server, regardless as to how busy it is. Thankfully, AWS state SQS Simple Queues support an almost unlimited TPS!
Continuing with the serverless theme, processing of messages on the queue is performed by AWS Lambda.
AWS Lambda
Lambda is the logic engine of the Application Tier – 3 Lambda functions will perform the following:
Register Contact Token – in response to synchronous API calls through the API Gateway, this Lambda will store the token in the database.
Report Contact – through polling of the SQS queue, this lambda will take contact reports, resolve the contact token to a user and if not a duplicate (i.e. the other user has already registered the contact), add store the contact report in the database.
Notify Infection – upon receiving a verified infection report, this Lambda will inform all recent contacts that they meet defined criteria to isolate.
Health professionals will also need to decide what do with a user who has reported an infection and continues to participate in the population? This will require even more logic, perhaps when registering a contact to check whether the contact is already infected and triggering the notification process (perhaps ensuring those who were previously informed are not informed again).
Data
Finally, the Data Tier where we store 40TB worth of data.
Firstly, this section attempts to explain the difference between centralised and decentralised contact tracing apps. Secondly it explains the volumetrics – how do we get to the 40TB figure? Finally, it explains the database choice, Elasticsearch.
Centralised vs Decentralised
One of the main areas of contention when it comes to creating Contact Tracing applications is storage. Should all the data be sent to some central database owned by an organisation (the UK Government, for example), or should data remain on end user devices in a decentralised way (note decentralised does not mean Distributed Ledger or Blockchain!).
The main concern regarding centralisation appears to be privacy – do you want the government to know where you are / have been? Well, that’s a myth in my opinion. Given a design such as the one used here, even with a centralised model, the central organisation cannot easily track known individuals. At least not without going through existing legal channels to resolve telephone numbers to identified individuals.
With a decentralised solution – a device may maintain a list of all contacts. When a user reports they’re infected, this could be broadcast to all devices to check their local cache – if they’ve come into contact with that person recently, they will be asked to isolate.
With a decentralised model, data analysis becomes almost impossible. However, once the data is centralised, it comes incredibly useful to a wide range of professionals.
The UK Government is aiming for a centralised model, and I couldn’t agree more.
Data Model & Volumetrics
What data are we going to be storing? We essentially have 2 data types:
- Contact – this is a user, it will include information such as their User ID, whether they’re infected, how long they’re in quarantine for, etc.
- Contact Report – the two contacts who came into contact, where and when the contact occurred
The volumes involved in the contact information is negligible (GBs), however, as you can imagine, it is not so negligible for the contact reports.
Let’s define a contact report as
- User A – 16 bytes
- User B – 16 bytes
- GPS – 16 bytes
- Timestamp – 4 bytes
Each contact report consists of 52 bytes.
If there are 48,000,000 people using the app daily resulting in an average of 50 reports per user ending up in the database (100 contacts per day, 50% duplicate reports) and each contact report is 52 bytes, in a year that will generate approx. 40TB worth of data!
This data needs to be stored somewhere where it can be efficiently stored and queried.
Elasticsearch
In deciding on the database, I was looking for extreme retrieval performance. Naturally a GraphDB such as Neo4j jumps out – after-all, logically contacts are just vertices and edges. However, when the Neo4j data-size calculator told me I had too much data – I was concerned. Furthermore, the master / slave architecture of Neo4j (all writes must occur on a single node) is concerning.
The alternative is Elasticsearch – a distributed data store built of indices that are stored on shards across a number of nodes. This distributed nature allows for distributed querying across the dataset, outperforming any other database on the market. Furthermore, the integration with Kibana to analyse the data provided an unrivaled end-to-end package.
So that’s it – we’re done. Now for the final question – what will it cost?
Cost
Ignoring the people cost, I’ve estimated the technology cost as follows (high-level estimates based on simplified AWS pricing).
| Service | Cost per Day ($) |
| API Gateway | 556 |
| SQS | 38 |
| Lambda | 19 |
| Elasticsearch Servers | 100 |
| Elasticsearch EBS | 80 |
| Cognito | 4,000 |
| Total | 4,793 |
Therefore, it’s approximately $143,790 per month, or $1,725,480 per year. There are also SMS costs to verify users, totaling $1,866,240 for the required population.
That’s a 1st year cost of $3,661,720, or £2,938,640.
Conclusion
Creating a Contact Tracing app is not as simple as making that Bluetooth.startAdvertising() call on a mobile phone. The call sets into motion a wealth of complexity that can only be solved by the amazing collaboration of engineers, politicians, medical professionals, and mathematicians to name a few.
Choosing between a centralised and decentralised solution has major implications as highlighted throughout this article. However, I believe the advantages of being able to analyse this data greatly outweighs the technical complexity and privacy concerns.
There are 500 million tweets a day – a contact tracing application has the potential to report on almost 5 billion contacts a day. These volumes are unparalleled and in my opinion can only be met through a serverless cloud architecture such as the one outlined in this article (although this took me a day to design so it’s probably full of holes!).
What are your thoughts? Is centalisation worth it? How would you improve on this solution? Is it worth £3m?
Thank you for reading and stay safe.
