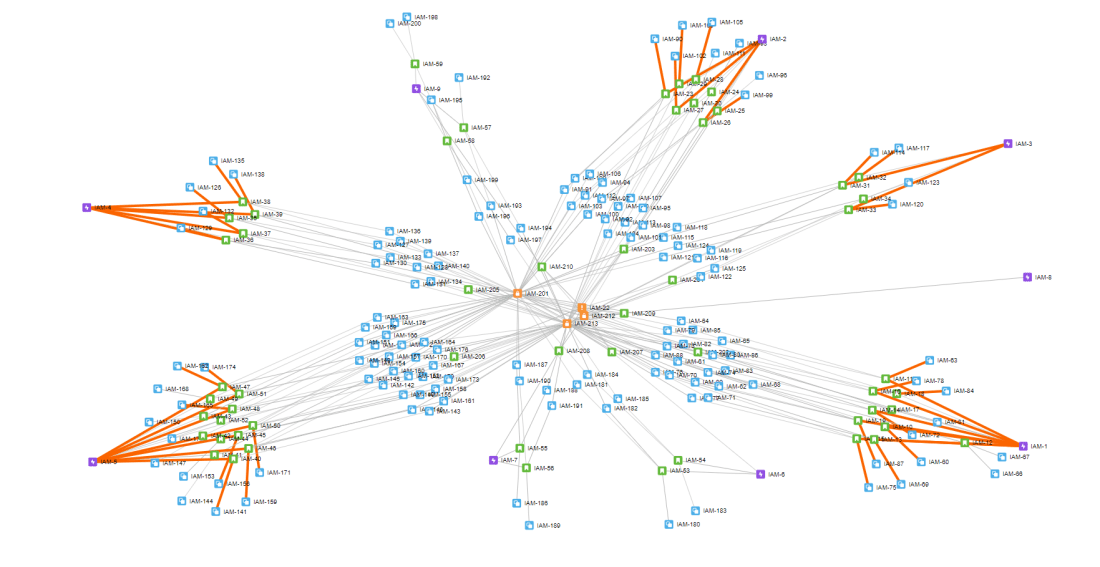
If you’re as frustrated with the lack of insight into your JIRA projects as I am – I’ve got the tool for you.
Use the JIRA Issue Visualiser, for free, and view the structure of your JIRA projects in less than a minute.
You’ll be asked to authorize via JIRA Cloud OAuth – once complete you can then paste in a JQL query. For example, to produce the above I just wanted to see all items within my project, so my query was ‘project=IAM’. You can read about JQL queries on the JIRA help-site if you are not familiar. You must be using JIRA Cloud and not a local JIRA installation to use this tool.
NOTE: this tool has been glued together in an evening. It is not user friendly or close to the finished article. However, in its current state, it can still be as useful to you as it is to me. If you’re interested in working on the tool, please see the bottom of this post.
Once you have provided a query, wait 20-30 seconds (you will just see a blank page whilst the data is retrieved).
You can click and drag the core JIRA issues (epics and stories) to organise the graph in a way that makes sense. You can also click on an issue to open it in JIRA.
NOTE: if the query returns more than 400 items at present, it may take longer than 20-30 seconds to load.
Why develop the JIRA Issue Visualiser?
Forget Agile, Scrum and Pillars – the successful completion of a project is dependent on the successful completion of a number of tasks inline with client expectations (cost, time, etc.) through a dedicated, talented team. Fundamentally, JIRA provides a way of organising those tasks into helpful chunks, and supercharges a collaborative approach to their completion. JIRA goes on to do 100x more, but at its core, it’s a task management system.
JIRA offers a number of great reports out of the box that attempt to give you a view of your project – however I feel they don’t give me a view on a page that tells me:
How dependent are my issues upon each other?
And in particular, what tasks are causing the biggest issues (RAIDs)?
What’s the status of my tasks?
How big / complex is the project?
I looked at a number of options – in particular using PowerBI plugins to create force-directed graphs, but they just weren’t flexible enough. Having used D3 before, I knew I could spin up something to meet my current requirements, but would also be flexible enough for the future. I created the JIRA Issue Visualiser and use it multiple times per day – I hope it can be as useful to you as it is to me.
Architecture
The diagram below outlines the high-level architecture for the JIRA Issue Visualiser – the core components include:
When the user retrieves the static HTML (and JavaScript) from S3, the code checks to see if there’s an access token available – if not, the user is redirected to the OAuth JIRA endpoint
The user logs into JIRA Cloud and authorises their credentials against the JIRA Issue Visualiser – following this, the user is redirected back to the resource in S3, with an authorisation code in the query parameters
The static page retrieves the authorisation code from the query parameters and sends it to AWS Lambda to be swapped for an access token
The Lambda function sends a request containing the authorisation code to JIRA (along with private credentials such as the client secret)
JIRA responds with the Bearer access token
The access token is returned to the users browser (note Lambda is stateless and therefore does not maintain any sort of application session – I didn’t want to integrate DynamoDB or similar at this point)
The user enters a JQL query which is sent to Lambda along with the access token
The call can not be made from the browser direct to JIRA due to CORS limitations on JIRA cloud and the resultant restriction this puts on browser CORS security
Lambda makes a call to the Issue Search REST endpoint, passing the JQL and access token. Due to the limitations of JIRA only returning 100 issues per API call, Lambda will make n number of API calls to retrieve all issues
JIRA responds with issue information including issue links and subtasks
The combined list of issues is returned to the users browser where it is rendered into a force-directed graph by D3
Future Enhancements
The code for the 2 Lambda functions and HTML / JavaScript can be found on GitHub – feel free to contribute (message me on LinkedIn to get started). This is by no means a finished product, future work could include:
Retrieving issues from JIRA concurrently
Remembering the access-token on page refresh so the user doesn’t have to re-authorise
Improve UI/UX (i.e. not using JavaScript prompts to retrieve a JQL query!)
Move the UI to a more future-proofed architecture (i.e. an SPA)
The ability to update force-directed graph properties (charge, gravity, etc.) on the page
Contextual menu containing useful information regarding the issue without having to click it
The query will display related nodes where the related node is a node also returned by the JQL query – it should work regardless
The Binary Tree Cameras problem focusses on the binary tree data structure, a form of graph. The high-level aim being to add a ‘camera’ to the least number of nodes such that every node is either a camera or has an edge that connects to a node with a camera.
Whilst this problem focusses on the tree structure, graphs are used extensively as the data structure behind many of the digital services we interact with on a day-to-day basis, such as:
Facebook Graph – modelling your friendships, posts, likes, comments, etc. to help provide a better user experience (i.e. Simon and John are both connect to the Sarah node, I’ll recommend John as a friend to Simon)
Google Maps – a road network is just a set of vertices with edges where you can transfer from one road to another. Google may use a graph to determine how to get from from vertex A to vertex B (with perhaps the edges containing information such as maximum speed, traffic volume, etc.). This is similar to routing protocols used on many corporate LANs / MANs
It’s obvious a good Software Engineer needs to understand trees and more generally graphs.
This post outlines my O(n) solution – every node of the graph is visited exactly once. This solution is faster and more memory efficient than all other accepted JavaScript solutions on LeetCode.
Approaches
Due to the use of a Binary Tree data structure, there are a number of constraints on the problem which make designing a solution a little easier (although I guess you don’t know what you don’t know, so I’m sure there’s a better way of solving this problem than mine!).
Ultimately you need to start at a node, traverse the tree in some way, and make decisions as to where cameras should be added – there are therefore three techniques:
Start from root node (Root-Down) – start at the top and work your way down to the leaf nodes.
Start at a random node – not sure how this would be sensible approach, but it’s an option!
Start at the leaf nodes (Leaf-Up) – starting at the leaf nodes, work your way back up to the root node.
Whatever approach is taken to solve the problem, there are two algorithmic approaches for traversing the tree:
If you’re interested in learning more about tree structures, understanding traversal techniques such as breadth-first and depth-first are also important – particularly as tree search techniques.
I believe recursion is the simplest technique for navigating a graph – however, it does have one major disadvantage; whether programming in a high-level language such as Java or writing in low-level assembly, the stack is a limiting factor. A stack grows upwards and has a reserved area in the main memory of a computer – processes are assigned a portion of the stack area in memory to grow into, and the growth occurs when, amongst other things, function calls are made.
When a function is called, essentially (true enough for the purpose of this paragraph) the state of the current function is pushed onto the stack, as well as a return address and the parameters sent to the next function (known as the stack frame). When the new function returns, everything is popped off, and the code continues from where it left off with the correct state. However, if a function doesn’t return and more and more function calls are made (i.e. a very large tree), too many stack frames are pushed onto the stack and the stack limit is breached causing an exception. This limit is often lower than you expect. You can see how this can be an issue for recursive solutions.
Whilst I had this issue in the back of my mind, I decided to progress and learn more about the problem using a technique I was comfortable with; thankfully none of the test cases breached this limit! However, for this reason, I’m not the biggest fan of my solution – I know it will fail for large binary trees.
Root-Down
Often times the best way to solve a problem is to just get started – whilst this technique may often not result in the final solution, it will provide an opportunity to learn more about the problem, rather than trying to theoretically think through the entire solution.
I began to solve this problem using a root-down approach but quickly realised the logic was booming too complex – demonstrated through the example below:
The algorithm may initially think the first node doesn’t have a camera and isn’t covered by one itself, so it makes sense to put one down. We then go down the left and right sub trees, following the rule such that if a node is ‘covered’ by a camera, don’t put a camera down.
The most efficient number of cameras for the above solution is 3 however, not 4. How could this be solved? We could implement some sort of lookahead, but it’s no longer a truly recursive solution, and certainly not O(n).
What about starting at the leaf nodes? We need some knowledge of the structure of the tree to make efficient decisions.
Leaf-Up
If you recursively visit each each node until you reach a leaf node (of which there could of course be multiple), you can begin to give the parent nodes some context as to whether or not a camera should be added. Implementing this algorithm will result in the below solution for the problem introduced above:
By modifying the rule slightly – if as a node, you’re covered by a camera or your parent is covered by a camera, do not place a camera if you have children nodes. You can see how this rule related in an efficient placement around A->B and A->E.
By starting at the leaf nodes, you can provide context to the decision making process which results in the efficient placement of cameras.
Analysis
This problem wasn’t particularly hard, but it did provide a couple of learning opportunities which are discussed in this section. They are:
Auto-generated Unit Testing
Optimising code, and
Parallel Computing
Auto-generated Unit Testing
The benefits of Test Driven Development (TDD) are well known, but as with the majority of testing approaches, it relies upon a human defining n number of scenarios that test the various use cases. It can be difficult if not close to impossible to tell whether you have the right level of coverage, because you don’t know what you don’t know. Solving LeetCode problems involves writing some code, running the tests, realising you didn’t cater for a certain scenario, updating your solution, and repeating. What if we weren’t given the outputs of the LeetCode tests? We were just told whether the solution is correct or not.
Thinking of this scenario and the fact that as humans we don’t know what we don’t know, would auto-generated unit tests be feasible? Could we let some code randomly create binary trees that we test against? The process would be:
Software creates a binary tree
Human inputs the expected value (so will only work for moderately sizes trees)
Solution executes and is compared against expected value
In this way, we don’t need to rely on human intelligence to understand the various scenarios… but how likely and how quickly will auto-generated unit tests find errors in a solution? This obviously depends on the complexity of the input you’re generating, but in this scenario anything more than 100 unit tests would probably begin to annoy me.
The code to run these automated unit tests is available on GitHub; by ‘breaking’ various parts of my solution (to mimc the development process outlined above), auto-generation of unit tests found these issues after, on average, 2.5 rounds. That took me by surprise – this could be a really useful technique going forward.
So if you’re working for Facebook and you want to test your recommendation engine, you could auto-generate social graphs to compare an updated solution output to the existing solution. If you work for Google and you’re updating your directions functionality, will you remember to write a test that goes through a small village with a railway crossing that stops cars for 5 minutes when the barriers are down? Does your updated directions functionality take account of this scenario? Again, the success of this approach depends on the probability of auto-generation creating a good distribution of units tests, but it’s an interesting thought.
Optimising Code
What about performance? What makes a solution faster than 96% of solutions as opposed to being faster than all other solutions? As it turns out, not much. The usual suspects always play a part (including as discussed in a preview blog post, the shared LeetCode execution environment):
Reduce (or better yet, eliminate) logging. Logging in NodeJS leaves the NodeJS environment (event loop) – this can be a costly process. Often time pre-compiler directives (in C for example) can be used to eliminate certain logging statements from even making their way into the final executable, potentially reducing an application size so much that it can fit entirely into main memory, with the benefits that brings.
Stop Assigning variables that aren’t used (or no longer serve a purpose) – the Node object of the input to the solution contains a val property – I used this property to identify which nodes had cameras (0 and 1) when logging. Once I had a working solution, this was a wasted operation… so remove it.
Think about your code and how it will be compiled down (or interpreted) – if you think about the code block below, we’re assigning two variables, executing some conditional statements, and again assigning some variables a value.
var leftResp = null
var rightResp = null
if (node.left) {
leftResp = recurseNode(node.left, true)
}
if (node.right) {
rightResp = recurseNode(node.right, true)
}
If this was in a compiled program, we’d have:
Some stack operations to reserve address space
Conditional logic including varying JMP commands as well as truth logic
Further stack operations (calling functions, assigning values, etc.)
Compare that with the below code which achieves the same:
var leftResp = node.left && recurseNode(node.left, true)
var rightResp = node.right && recurseNode(node.right, true)
If this were to be compiled down, we’d have:
Some stack operations to reserve address space
Some some truth logic
Some more stack operations (calling functions, assigning values, etc.)
Now whilst the AND statement may result in some JMP commands to ensure the rhs does not execute if the lhs is false, this refactoring did result in a faster execution time. At a high level, less CPU instructions results in a faster execution time.
Parallel Computing
How else could we improve the performance of the solution that isn’t just optimising code? We could parallelise the solution. Whilst NodeJS is inherently single threaded following an event loop architecture, it does support support multi-threading through Workers. Could the solution be modified such that where a node branches off with 50% of nodes on one branch and 50% on the other (in the ideal world), we spin up an additional worker to execute in parallel (note not concurrently, we’d be making use of multi-processor architectures). However, much as calling functions and the resultant context switching has a performance impact (and generally makes recursive solutions slower than their iterative counterparts), so too does parallelising your code. Creating and destroying threads is a costly process.
Whilst parallelising the solution would have the aim of improving execution time, it has no impact on the computation complexity, it would remain O(n) as we must still visit each node once.
Conclusion
As with anything in life, knowledge and experience go hand in hand. To make the best decisions, you need both – ultimately a lack of experience will lead to errors and therefore more experience. As a Software Engineer, this experience leads to an intuition whereby you can tell when it’s worth abandoning a solution and looking elsewhere. Following a Root-Down approach, I got the feeling the solution wasn’t as clean as it could be (simply down to lines of code), so I decided to try something else. Trusting your intuition as a Software Engineer is extremely important.
Further to this, you may want to develop the perfect solution, but sometimes this is not possible and / or required. In this example I know my recursive solution wouldn’t work for extremely large trees, however it meets all the requirements outlined by the LeetCode Unit Tests. Understand (which often involves communicating with stakeholders) whether the scenarios not covered by your solution are likely to ever occur and are therefore worth the extra investment to cater for.
The Least Frequently Used (LFU) Cache problem brings together a number of Computer Science techniques and principles to solve a very “Computer Science’y” problem.
In summary, the problem asks you to build a cache that could mimic the behavior found in hardware caches (i.e. CPU caches) as well as software based caches (i.e. Redis, memcached, etc.). The cache is composed of key:value pair objects.
The problem is essentially structured into 3 areas:
Intialising a cache of a given size
Supporting the addition of items to the cache such that if the cache is full, the least frequently accessed item is removed (to make space) and the new item added.
If the item already exists in the cache, its value is updated and the frequency of that item being accessed is increased by 1
Supporting the retrieval of items from the cache such that each retrieval updates the frequency at which the retrieved item is accessed, as well as when it was last accessed (and importantly in relation to when it was last accessed, when compared with items accessed at the same frequency)
My O(1) JavaScript solution was 99.31% faster (although this measurement isn’t particularly fair as the environment is not the same for each run (i.e. it’s a shared environment)) and 100% more memory efficient than all other accepted JavaScript solutions.
Approaches
In the problem description, it mentions that a solution of complexity O(1) is desirable – meaning the retrieval or addition of an item takes the same number of steps, irrelevant of the item or the size of the cache (from a computational perspective – obviously larger software caches may perform slower where hardware caching, virtual memory and paging come into play).
Ignoring the O(1) requirement, I identified two possible solutions:
Iterative approach (not O(1))
Doubly Linked-List approach (O(1))
Iterative Approach
The initial approach that comes to mind is to split the items into buckets based on frequency, with the buckets containing an array of items. The item at the top of the array is the most recently accessed item for that frequency. This is demonstrated in the diagram below:
The issue with this solution is that in order to determine whether an item is in the bucket, you must loop through potentially all the items in the bucket. This prevents the solution from achieving O(1) and is more O(n).
Other issues I encountered with this approach around around maintaining index pointers into the array and the complexity this introduced when items are removed in particular. Essentially, I found a loop was always required (although I’d love to see an O(1) solution for this approach if it exists!).
Doubly Linked-List Approach
In order to achieve O(1), a solution must be designed such that, in simple terms, there are no loops or recursion (which are valid approaches to solving the problem). Whereas the previous solution relied on buckets and loops to look through all the items, an O(1) solution must therefore utilise a different data structure(s).
The first doubly linked-list creates a set of buckets that contain items based on the frequency at which they’re accessed
The second doubly linked-list (the root of which is the ‘data’ segment of the first doubly linked-list – the frequency bucket) stores the items in order of last accessed
This is particularly useful when wanting to delete the least frequently accessed item
This data structure on its own does not meet our O(1) requirement; if we wanted to determine whether an item exists, we’d have to traverse each bucket and the items within each bucket (a complexity of essentially O(n)). The solution is simple, maintain a dictionary which points to the items within the doubly linked-list structure.
There are additional minor details which won’t be expanded upon in this post, but I invite you to critique the solution on GitHub.
Analysis
This problem was definitely less of a thought experiment and more of a problem you may come across during a career as a Software Engineer. My takeaways are as follows:
Understand when a solution will benefit from a more rigid approach – apart from scribbling a bit-part solution on paper, I started development straight away. The doubly linked-list solution naturally developed and therefore I hadn’t coded for it to be reusable or use a reusable library. This resulted in some code duplication and generally increased the difficulty of debugging the solution. Obviously if I was to productionise a solution such as this, I would refactor to use a library implementation of a doubly linked-list that was well tested.
Having a basic understanding of computational complexity is important for all software engineers – regardless as to whether you’re developing for embedded systems or consumer websites. Problems can be solved in any number of ways, but its not usually until scaled out (not least in the enterprise) that the way the problem was solved becomes important. By understanding the impact of your solution, you’ll save on some pain further down the road.
All software boils down to data structures and algorithms. You may have been taught about them at University and now subconsciously use them in your job; or you may have never studied them but as a Software Engineer find yourself using them naturally. Having an understanding of the common data structures (linked lists, stacks, dictionaries, etc.) and how to operate upon them can increase the speed at which you develop reliable, quality code (especially if using libraries). Data Structures and Algorithms are not just topics to be studied for exams – keep them at the front of your mind.
Conclusion
I’ve solved many problems on other ‘coding’ challenge sites such as Project Euler – these problems can often seem too theoretical to take any practical lessons from. It’s been enjoyable to solve a problem that is Computer Science focused – whilst I didn’t learn as much as I may do when compared with a Project Euler problem, it has reinforced some Computer Science theory and the importance of it in your day-to-day job as a Software Engineer.
Max Points on a Line is the third least accepted (against submitted solutions) problem on LeetCode; it is also the second hardest problem in the ‘hard’ category. At first glance, the problem seems simple – from a set of points, determine the longest straight line that can be formed from those points and return the number of points in the subset. However, as the saying goes, if you assume it makes an ass out of u and me.
This is my write-up detailing the approach I took to solving the problem and the issues I encountered along the way. Lessons learnt can always be taken from one context and applied to another – hopefully you find this useful.
Approaches
I explored two options when it comes to solving this problem, both explained below. An ‘agricultural’ approach which I quickly abandoned, and a ‘formulaic’ approach that did work but encountered some interesting issues.
Whilst I won’t be posting my solution in this article, you can find my implementation on GitHub (linked in the Social Banner above).
Agricultural
Having forgotten some high school mathematics – my brain instantly went trying to understand how an algorithm based on scanning and or recursion / iteration could solve the problem. Could I determine the ‘step’ between two points and then for each remaining point, see if I continue the step pattern whether or not the point in question would be reached.
The algorithm quickly became complex – you would obviously need to check the step in both positive and negative directions (reducing performance), you may want to start finding the point in the line that would be closest to the point your analysing to slightly improve the performance, etc.
Good problem solving doesn’t mean coming to the correct solution first time – it’s also recognising when an approach isn’t working and looking for another way. y = mx + b.
Formulaic
The straight line equation in its well known form will determine y for a points associated x where the slope (m) and y-intercept (b) of the line are known.
My initial approach was to take two points in an existing line (any two points can be the start of a line) and determine their slope m = ( (y1 – y2) / (x1 – x2) ). The remaining variable to determine was the y-intercept which with the formula rearranged stated b = y – mx. I knew the slope from the previous calculation and I know x and y from an existing point so I could determine b, the y-intercept. The final step was to determine if for the given x of the point being analysed, given the y-intercept and the defined slope, did the resulting y == y of the point being analysed.
The approach worked – I went from passing 50% of the test cases using the agricultural approach to passing approx. 90%. But what was causing the final 10% to fail? Precision.
In day-to-day life as a Software Engineer, precision doesn’t usually impact you unless you’re working on financial systems, sensor based system, and other similarly complex, numerically focussed applications.
My solution was based on JavaScript which by default represents all floating point numbers as 64-bit floats. This means a number with a fractional component can be represented up to 17 decimal places, and even then may not be accurate. Both of these limitations caused issues.
The following test case enabled me to identify the issue:
[[0,0],[94911151,94911150],[94911152,94911151]]
Whilst the final two points are very close to each other, when on a slope with 0,0, all three do not form a straight line. If we try to determine the slope of the line containing the first two points, we would calculate -94911150/-94911151 – the answer according to the JavaScript engine is 0.9999999894638303. To determine the slope between the first and third point, we would do -94911151/-94911152 – the answer according to the JavaScript engine is 0.9999999894638303. Brilliant! All three points are on a straight line! But they’re not…
Use a high precision calculator and you’ll see that -94911150/-94911151 = 0.999999989463830230022181482131641201991112719726684170124541003617161907 and -94911151/-94911152 = 0.999999989463830341033053734296682016882483946670460811601991723796588202.
You can see around digits 16/17, the answer begins to vary… the slope is not the same. However, due to JavaScripts (although this problem isn’t limited to native JavaScript) precision limit and accuracy issues (i.e. rounding) mean that for this problem, I am unable to correctly to determine the slope. So, how do you solve the problem?
Initially I knew I had a precision error, but I wasn’t sure whether it was determining the slope, y-intercept, and y value for the cross-comparison. My first thought was do I need to determine the y-intercept and the y value? Surely if two points are on the same slope as two other points on the line, we’re good. Having removed the other elements, I noticed the precision issue above.
My immediate thought was that by using 0,0 as a comparison point, we were working with an answer for the slope that was extremely precise. If another point was used, the result may not require the same precision. If points 2 and 3 form the input were used to determine the slope, the result would be 1 (-1/-1). As 1 != 0.9999999894638303 – we pass the test case. This solution worked for all test cases and the ultimate acceptance of the solution. However, it’s obvious to see for test cases that result in a similar precision no matter what points are selected, the solution would encounter problems.
Analysis
LeetCode provides some great solution analytics – at the time of solving the problem, my solution execution time was 79% faster than other JavaScript solutions. My assumption is that that these solutions may have taken more agricultural approaches.
There are a few key takeaways from working through this solution:
All programming languages have limitations (of which some can be solved with third-party libraries – in this case, several BigNumber libraries). Whilst they may not impact you day-to-day, if you’re encountering ‘strange’ issues, they’re good to have in the back of your mind. Worse, often the runtime won’t throw any errors to tell you it has automatically rounded a result or is not accurate past a certain point.
Formal Specification techniques are used in critical systems to at runtime ensure code is behaving according to some mathematical constraints. Whilst formal specifications may not be necessary for all projects, there’s nothing wrong with having code to check the validity of results. For example, if adding two decimals both with two digits following the decimal point, the result won’t have more than two digits following the decimal point. If it does, you know something has gone wrong.
Understand what the minimum required steps are to solve the problem – my initial formulaic approach trying to understand the y value was adding complexity to the solution and making it harder to debug. I only needed to calculate the slope to solve this problem.
Another bug I encountered was due to not fully understanding the specification – my assumption (the second time I assumed wrong in solving this problem!) was that the points had to be consecutive according to the step function. This wasn’t the case and was not clearly stipulated in the problem description.
Conslusion
This problem was great fun to solve. Day-to-day in the workplace, my clients are using software in ways were these sorts of problems do not manifest themselves. But they exists – it’s important as a Software Engineer to be aware of them and to challenge yourself in ways that you may not be challenged in your day job (not that it lacks its own unique set of challenges!).
Apart from the usual cliches such as testing is only as good as the test cases and not fully understanding requirements is the downfall of many IT projects, I will take two ideas from this exercise:
Testing can be built into your code – if the result of performing an action is that n number of things should be in a list (without knowing the contents), add some code to check that n things are in the list. If not, an issue must have occurred (either data or code)
Understand what the minimum required steps are to solve the problem – initially you may just want to solve a problem, with the result not being the most elegant solution. Even if you don’t encounter issues, refactoring is important. It results in less instructions, potentially leading to less bugs in future; for those bugs that do occur, the solution will be easier to debug.