Whether trying to understand natural language processing or the intent of some software written in a given programming language, understand language syntax is a key Software Engineering challenge. Understanding the structure of a language is achieved through an understanding of the language grammar. But what is a grammar?
the whole system and structure of a language or of languages in general, usually taken as consisting of syntax and morphology (including inflections) and sometimes also phonology and semantics.
Google Dictionary
The Parse Lisp Expression LeetCode problem touches on this through a challenge that requires you to parse an expression that conforms to a given syntax and execute it – this is commonly known as interpretation. JavaScript is an example of an interpreted language, but even then, that’s often debatable. If we’re not executing machine instructions directly on a processor that correspond specifically to the given input, we must figure out what the intention of a certain input is, and then use instructions that are available for execution on the processor (from the host environment) to execute the intent; due to this additional interpretation step, interpreted code is therefore inherently slower than ‘native’ compiled code.
This post first explains the solution, but then touches on a grammar parsing tool, ANTLR, which offers a more robust, logical approach to language parsing. ANTLR was not used in the solution to the LeetCode problem as external libraries cannot be used in solutions.

Approaches
In solving this problem, I considered two approaches:
- regular expressions, and;
- iteration and / or recursion.
I intended to solve this problem using JavaScript; that constraint influenced the implementation approach. Specifically, the parsing of brackets within a statement was not possible with JavaScript’s regular expression handling ‘engine’.
(let x 2 (add (let x 3 (let x 4 x)) x))For example, in the above statement, JavaScript regular expressions (which themselves, are interpreted) are limited in their ability to support look-aheads and look-behinds, meaning that the nested brackets in this statement cannot be understood correctly.
I therefore had to use an iterative / recursive solution.
Solution
We know from the problem description that the statements fit into the following syntax; it has the following grammar:
add <expr1> <expr2>
mult <expr1> <expr2>
let (<v1> <expr1>)* <returnExpr>The approach to solving this problem is to read words (tokens) from left to right, executing as and when required. Note how brackets are parsed – they introduce the concept of a context which is explained below.
(let x 2 (add (let x 3 (let x 4 x)) x))Parsing of the above statement will:
- Recurse the expression (let x 2 (add (let x 3 (let x 4 x)) x))
- Assign x = 2
- Recurse the expression (add (let x 3 (let x 4 x)) x)
- Recurse the expression (let x 3 (let x 4 x))
- Assign x = 3
- Recurse the expression (let x 4 x)
- Assign x = 4
- Return 4
- Return 4
- Return 4 + 2
- Recurse the expression (let x 3 (let x 4 x))
- Return 6
The important thing to ensure in the implementation is that when the context changes (i.e. you encounter a left bracket), the state of any variables within preceding let expressions are assigned. For example, before executing the add statement in the above, x is first assigned the value of 2. It’s also important that the current context is remembered such that upon returning to the source context, it can be restored.
Improving the Solution
There are a number of areas wherein the solution could be improved; it was by no means the fastest JavaScript solution on LeetCode (only outperforming approximately 80% of other JavaScript solutions in terms of time complexity). There are two primary areas where performance could be improved:
- Assign variables more efficiently when executing the interpreted statement – as explained above, when executing an expression within a let expression, the ‘context’ must be set such that any variables used within the sub-expression are available. The inefficiency in the solution is that all variables are assigned (and sometimes multiple times) every time a sub-expression is reached, even if they haven’t changed.
- When executing a sub-expression, the state of any variables must be sent to that sub-expression as the context, however, upon returning to the initial expression, the context must be ‘reset’. As JavaScript passes objects by reference, we cannot pass the same object around as assigning a value to an existing property would overwrite the original value, or context. JavaScript does not have a straightforward way of cloning an object (especially deep cloning an object) – the approach taken was to convert the object to a string and then back into an object… obviously inefficient.
But what if we’re working with a complex language – something whereby we need a robust approach to parsing the grammar. This is where ANTLR can be used.
ANTLR Grammar Parsing
What is ANTLR?
ANTLR (ANother Tool for Language Recognition) is a powerful parser generator for reading, processing, executing, or translating structured text or binary files. It’s widely used to build languages, tools, and frameworks. From a grammar, ANTLR generates a parser that can build and walk parse trees.
antlr.org
In the context of this problem, ANTLR is used to parse the input statement into a structure that software can easier interact with than just a string of characters; the structure is a graph known as a Parse Tree. Graphs form the solution to a number of problems on my blog; understanding graphs is vital for any Software Engineer.
There are three stages to execute an interpreted statement, they are:
- Parse the syntax;
- Validate the semantics, and;
- Execute the statement.
Parsing the syntax turns the ‘program’ into a navigable set of ‘tokens’ in the form of a parse tree. This enables the semantics of the statement to be validated (i.e. are we adding to a variable that does not exist). Given both the syntax and semantics validate successfully, the parse tree can be executed.
The parse tree for the example statement above resembles the following:
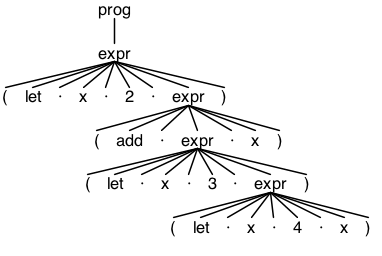
You can see from this tree structure, the walking algorithm follows a depth first approach, flowing from the left most leaf node to the right.
So how does ANTLR generate this tree structure? The answer is through a grammar definition, executed against some input program – the grammar to parse the LISP expression syntax as outlined in the LeetCode problem description can be found below.
grammar Expr;
prog: expr;
expr: '(' 'let' ' ' (VAR ' ' (expr|VAR|INT))+ ' ' (expr|VAR|INT) ')'
| '(' ('add'|'mult') ' ' (expr|VAR|INT) ' ' (expr|VAR|INT) ')'
;
VAR: [a-zA-Z0-9]+ ;
INT: [0-9]+ ;The grammar is relatively straightforward to understand – it follows a similar syntax itself to regular expressions but is known as Backus–Naur form. The program is made up of an expr, for which there are structurally two types of expression, a let and an arithmetic expression (add or mult).
Interestingly, in order to parse the grammar file provided, ANTLR itself will utilise a defined grammar to parse the input grammar.
You can therefore see how defining a grammar with a tool such as ANTLR provides for a much more robust environment when compared with the initial solution explained earlier in this post.
Conclusion
Often, your implementation won’t be impacted by the chosen programming language. Certainly, whilst the computational complexity of a solution may be the same in two ‘languages’, the time complexity may differ wildly; something you may want to consider given your non-functional requirements. Solving this problem did however introduce a language / run-time limitation in JavaScript’s support for regular expressions which is not as advanced as say Java’s.
Finally, learn. The complexity (effort, cost, computational, etc.) of a solution should always be proportional to the problem – but that’s not to say you shouldn’t be curious as to how else a problem can be solved. Understanding how tools such as ANTLR work give you, a Software Engineer, another tool in your kit – opening up alternative ways to solving problems in future.